Extract Tables from PDFs with Automation
scraping data
pdf file
Introduction
Handling data in PDF format can be frustrating, especially when you need to extract structured tables for analysis or automation. Manually copying and pasting data isn’t just time-consuming—it’s also error-prone. That’s where automated table extraction comes in, making it easier to retrieve structured data efficiently from PDFs.
This process can be categorized into two approaches: text-based PDF extraction and Optical Character Recognition (OCR).
- Text-based PDFs: Specialized tools analyze the document’s internal structure, detect table boundaries, and extract data in structured formats such as CSV or DataFrames.
- Optical Character Recognition (OCR): OCR tools convert scanned images into machine-readable text, enabling further processing to identify and extract table structures, even from non-text PDFs.
By automating table extraction, businesses can streamline workflows, reduce manual effort, and ensure data consistency—whether it’s financial reports, invoices, or research documents. With the right tools, retrieving valuable insights from PDFs becomes seamless and scalable.
Data Source
For this project, we utilize a sample PDF file provided by the Tabula library:
pdf_path = '../pdf/resources/data.pdf'
This file serves as a standardized dataset for all extraction processes, allowing us to compare different methods and evaluate their effectiveness in retrieving structured data.
The Code
By calling scraping_pdf.read_pdf, we can detect all text and table in pdf file. this function needs input types to determine which process will be used. Currently this param can be input one of this value ['tabula', 'camelot', 'plumber', 'pymupdf', 'tesseract'].
The parameter flavor is determine which mode we used to scan the table in PDF file. The mode can we categorize into 4 type, namely:
- Lattice mode is good for tables with visible borders. This mode more deterministic in nature, and it does not rely on guesses. It can be used to parse tables that have demarcated lines between cells, and it can automatically parse multiple tables present on a page.
- Stream mode is good when the tables lack visible borders. This mode can be used to parse tables that have whitespaces between cells to simulate a table structure.
- Network mode parser is text-based: it relies on the bounding boxes of the text elements encoded in the .pdf document to identify patterns indicative of a table.
- Hybrid mode parser aims to combine the strengths of the Network parser (identifying cells based on text alignments) and of the Lattice parser (relying on solid lines to determine tables rows and columns boundaries).
scraping_pdf.read_pdf(pdf_path, types='tabula', pages='all', flavor= 'stream', is_safe=False, output= 'table', bbox=None)
This function requires the following parameters:
- pdf_path(
string): pdf file path - types (
string): type of process - pages(
string): which page that we want to detect - flavor (
string): modes of scanning - is_safe(
boolean): safe file - output (
string): output name - bbox (
string): type of process
The result
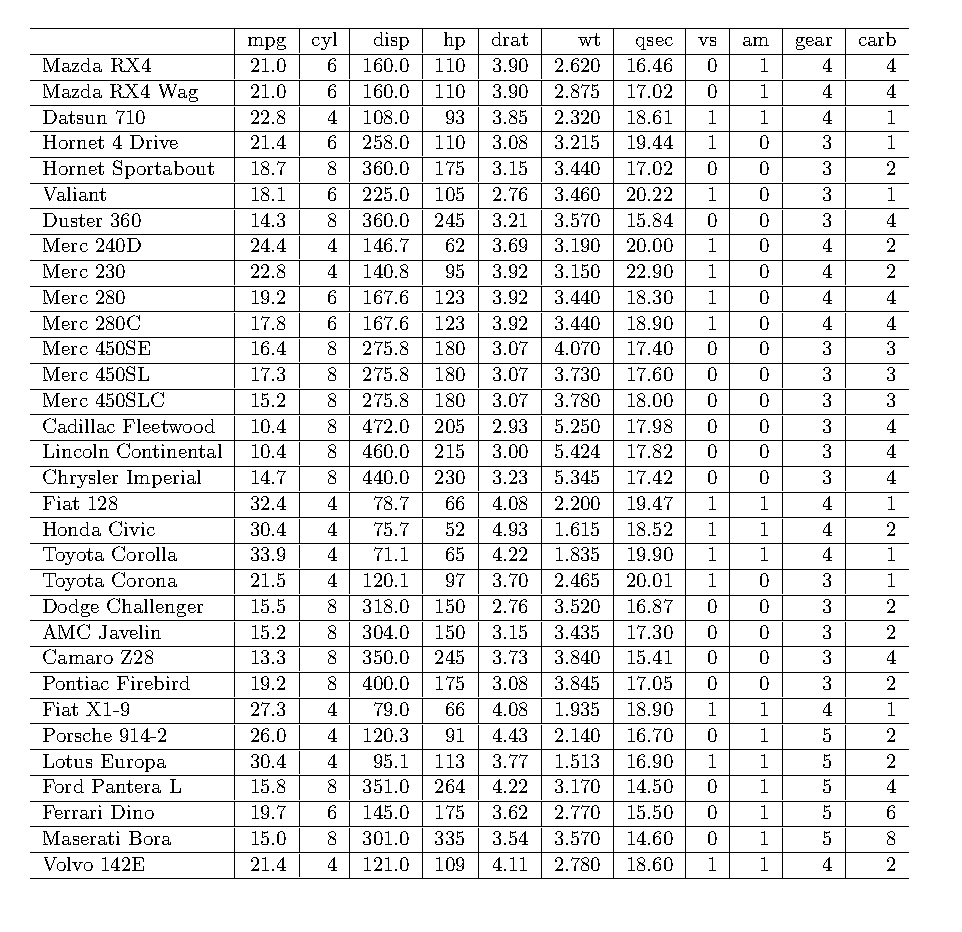
Tabula
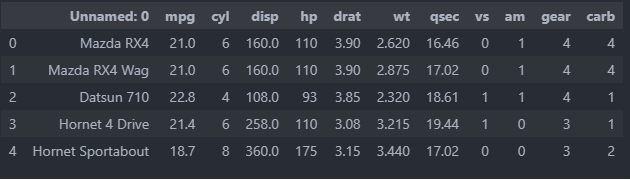
This method is only really works with simple tables. The advantage of this method is that it is simple to execute and quick to run. It struggles, however, with tables that have merged cells or irregular formatting.
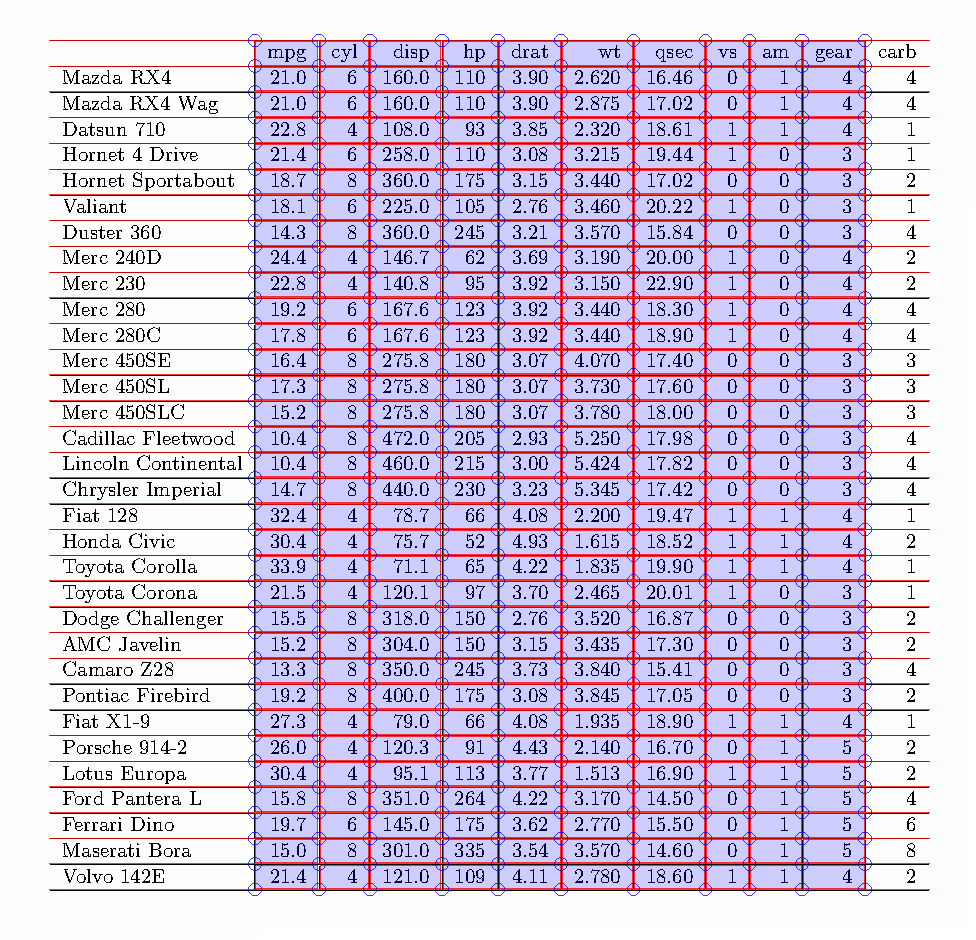
Camelot
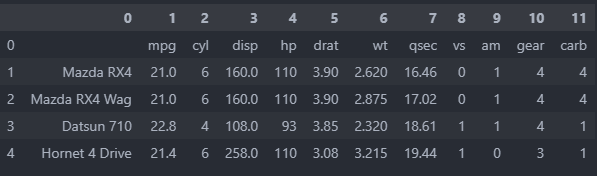
This method is can handle somewhat more complex tables compare to previous method.
Plumber
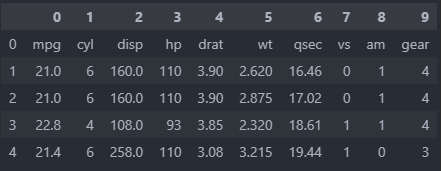
If our tables are too complex, then using plumber is one of the solution. It also helps extract not only tables, but also text. One has more control over what one wants to extract because one can manually define table areas — that being said, this does require more fine-tuning than a “just run it”-type of approach.
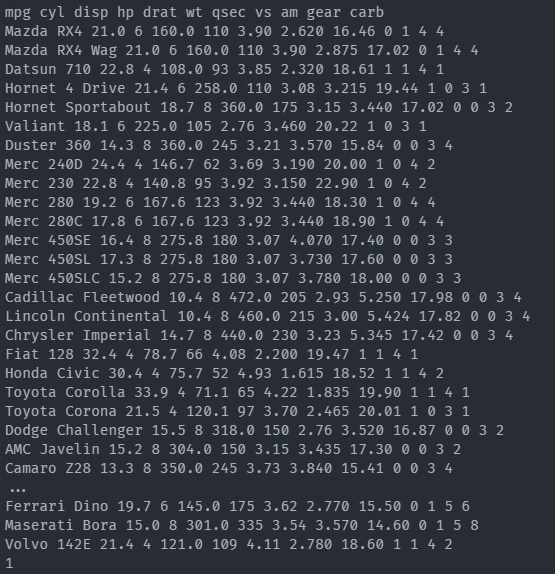
pymupdf
'mpg\ncyl\ndisp\nhp\ndrat\nwt\nqsec\nvs\nam\ngear\ncarb\nMazda RX4\n21.0\n6\n160.0\n110\n3.90\n2.620\n16.46\n0\n1\n4\n4\nMazda RX4 Wag\n21.0\n6\n160.0\n110\n3.90\n2.875\n17.02\n0\n1\n4\n4\nDatsun 710\n22.8\n4\n108.0\n93\n3.85\n2.320\n18.61\n1\n1\n4\n1\nHornet 4 Drive\n21.4\n6\n258.0\n110\n3.08\n3.215\n19.44\n1\n0\n3\n1\nHornet Sportabout\n18.7\n8\n360.0\n175\n3.15\n3.440\n17.02\n0\n0\n3\n2\nValiant\n18.1\n6\n225.0\n105\n2.76\n3.460\n20.22\n1\n0\n3\n1\nDuster 360\n14.3\n8\n360.0\n245\n3.21\n3.570\n15.84\n0\n0\n3\n4\nMerc 240D\n24.4\n4\n146.7\n62\n3.69\n3.190\n20.00\n1\n0\n4\n2\nMerc 230\n22.8\n4\n140.8\n95\n3.92\n3.150\n22.90\n1\n0\n4\n2\nMerc 280\n19.2\n6\n167.6\n123\n3.92\n3.440\n18.30\n1\n0\n4\n4\nMer
This method cannot recognize tables as such. However, when other methods fail, it can be a way to extract the necessary data. One can then add the tabular structure afterwards during data cleaning. It can also extract images and metadata from PDFs, which makes it a good general-purpose PDF wrangler.
tesseract
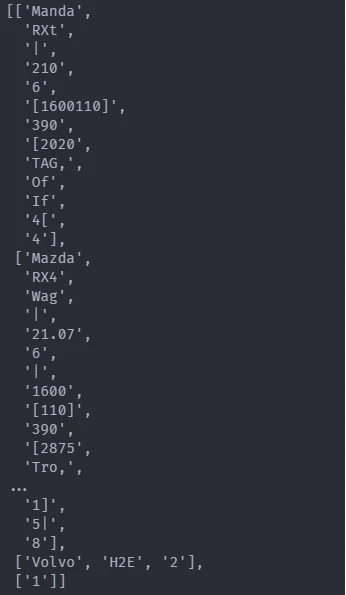
Sometimes, all methods listed above fail. This can be due to two reasons:
- Either the document is not text-based but scanned.
- The document is text-based but with an atypical encryption that Tabula & Co. cannot handle.
When this is the case, it is best to treat the PDF as an image and use OCR technology to read it. Tesseract is by far the most widespread tool for doing this.
source
- https://medium.com/data-science-collective/stop-copy-pasting-turn-pdfs-into-data-in-seconds-c5997d523133